Wer DBF aus einem fahrenden Zug heraus aufruft, kann seit heute nur per GPS-Position Informationen zu diesem Zug erhalten – zumindest in den meisten Fällen und mit ein paar Einschränkungen. Ich möchte hier das Konzept dahinter erläutern.
Da über GTFS derzeit nur Solldaten zur Verfügung stehen und das HAFAS Zugradar lediglich nach beliebigen Fahrten im Umkreis sucht, ohne dabei konkrete Strecken zu berücksichtigen, greift die DBF-Implementierung nicht darauf zurück.
Stattdessen hat sie als einzige API-Abhängigkeit die Ankunfts-/Abfahrtstafel für Bahnhöfe und berechnet alles weitere selbst. Auch bei Abschaltung des HAFAS Zugradars bleibt sie funktionsfähig.
Abbildung von Positionen auf Nachbarstationen
Kern der Lokalisierung ist eine Datenbank, die Deutschland in ca. 200m × 300m große Rechtecke einteilt¹. Für jedes Rechteck, das mindestens eine Bahnstrecke enthält, listet sie alle Bahnhöfe auf, die von einem diese Bahnstrecke passierenden Zug planmäßig als nächstes angefahren werden. Eine Position auf dem Tunnel durch den Teutoburger Wald bei Lengerich enthält beispielsweise unter anderem
- Lengerich (Westf) und Natrup-Hagen (RB66),
- Münster (Westf) Hbf und Osnabrück Hbf (IC/ICE Linien 30 und 31) sowie
- Essen Hbf und Hamburg Hbf (IC-Verbindung Hamburg – Ruhrgebiet ohne Unterwegshalte).
Die Datenbank beruht derzeit überwiegend auf dem von NVBW bereitgestellten SPNV GTFS-Liniennetzplan. Dieser enthält erfreulicherweise auch RE- und RB-Linien außerhalb von Baden-Württembeg. Erweitert wird sie mit einer (leider unfreien und unvollständigen) Menge an IC/ICE- und S-Bahn-Verbindungen. Für Hinweise zu weiteren offenen Datenquellen mit Liniennetzangaben bin ich dankbar.
Bestimmung von Zugkandidaten
Auf Basis einer GPS-Position werden zunächst die Nachbarstationen aus der Datenbank geholt und dann die Ankünfte der nächsten zwei Stunden an jeder Station abgefragt. Dieser Vorgang kann bei einer großen Menge an Stationen einige Sekunden dauern, da die Abfragen nicht parallel stattfinden. Zwar wäre die dadurch ausgelöste zusätzliche Last verglichen mit den restlichen (durch Menschen verursachten) HAFAS-Anfragen noch nicht einmal messbar, zu viele parallele Anfragen von einer einzigen IP dürften aber dennoch nicht gerne gesehen werden.
Für jede Zugfahrt sind Soll- und Ist-Zeit der Ankunft an der angefragten Station sowie die Namen und Soll-Abfahrtszeiten aller vorherigen Stationen bekannt. Züge, die an mehreren der angefragten Stationen verkehren, sind mehrfach vorhanden und werden zu einer einzigen Zugfahrt vereinigt. Nun geht es daran, für jeden Zug abzuschätzen, ob er sich gerade an der angefragten Position befinden könnte oder nicht.
Da die Datenbank mit Paaren von Stationen gefüttert wird, fliegt zunächst jeder Zug raus, der nur eine der angefragten Stationen passiert. Bei solchen Zügen ist sehr wahrscheinlich, dass sie die gesuchte Position auf ihrer Strecke nicht passieren. Anschließend wird für jeden Zug mit Hilfe der (bekannten) Verspätung an der angefragten Station die (unbekannte) verspätung an den vorherigen Unterwegshalten geschätzt und anhand dieser Echtzeitdaten bestimmt, zwischen welchen beiden Unterwegshalten er sich gerade befindet. Ebenso wird für jedes Paar von Unterwegshalten die Entfernung zwischen der angefragten Position und der Luftlinie zwischen den Halten bestimmt.
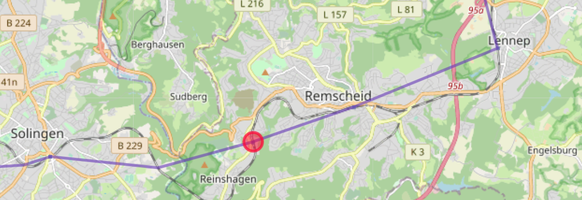
Jetzt fliegen alle Züge, deren aktuelle geschätzte Position sich nicht zwischen dem Paar von Unterwegshalten mit der kürzesten Entfernung zur angefragten Position befindet. Denn diese sind gerade sehr wahrscheinlich nicht auf dem richtigen Streckenabschnitt. Ebenso werden Züge verworfen, die sich noch an der Startstation befinden und nicht innerhalb der nächsten fünf Minuten losfahren. Eine S-Bahn, die erst in einer Stunde losfährt, ist wohl kaum gerade auf einer Bahnstrecke unterwegs oder auch nur einstiegsbereit am Bahnsteig.
Für die verbleibenden Züge wird die aktuelle Position auf der Luftlinie zwischen ihren Halten geschätzt. Dabei gehe ich von konstanter Geschwindigkeit aus, da ich keine Beschleunigungsprofile oder Streckengeschwindigkeiten kenne. Anschließend werden die Züge sortiert nach der Entfernung zur gesuchten Position aufgelistet.
Genauere Positionsabschätzung
Mit Verwendung des tatsächlichen Linienverlaufs einer Fahrt anstelle der Luftlinie zwischen Unterwegshalten ließe sich die Position noch viel genauer abschätzen und insbesondere bestimmen, ob die Route eines Zuges überhaupt die gesuchte Position enthält – wenn nicht, kann er direkt verworfen werden, auch wenn er nur wenige km neben der gesuchten Position auf einer anderen Bahnstrecke entlangfährt.
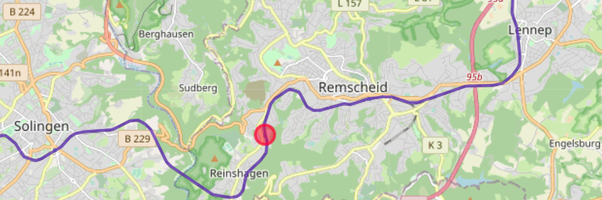
Diese Verbesserung ist derzeit nicht implementiert, da das die Menge notwendiger API-Anfragen nochmals erhöhen würde und ich zunächst testen möchte, ob die Ergebnisse mit linearer (Luftlinien-)Interpolation bereits hinreichend nützlich sind. Außerdem kommt es regelmäßig vor, dass das HAFAS die Linie selbst falsch einschätzt und z.B. einen ICE auf einer nicht elektrisierten Nebenbahn (statt der einige km entfernt verlaufenden, aber insgesamt längeren, elektrisierten Hauptbahn) platziert.
Ebenso wäre es auf Dauer interessant, anstelle der Entfernung zur Position die Zeit bis zum Erreichen (oder seit dem Erreichen) der Position als Gütemaß zu verwenden. S-Bahnen und ICE sind ja durchaus unterschiedlich schnell unterwegs. Das steht noch auf der Todo-Liste.
Quelltext
Die Implementierung ist noch ein wenig frickelig und undokumentiert, aber selbstverständlich auf GitHub verfügbar: derf/geolocation-to-train.
Fußnoten
¹ Der Einfachheit halber werden auf drei Nachkommastellen gerundete GPS-Koordinaten genutzt. Das resultierende Gitternetz ist unseren Breitengeraden nicht quadratisch.