Measurement Automation with Korad Bench Supplies
A few years back, I bought an RND Lab RND 320-KA3005P bench power supply both for its capability of delivering up to 30V @ 5A, and for its USB serial control channel. The latter can be used to both read out voltage/current data and change all settings which are accessible from the front panel, including voltage and current limits.
This weekend, I finally got around to writing a proper Python tool for controlling and automating it: korad-logger works with most KAxxxxP power supplies, which are sold under brand names such as Korad or RND Lab.
Now, basic characteristics such as I-V curves are trivial to generate. For instance, here's the I-V curve for an unknown RGB power LED.
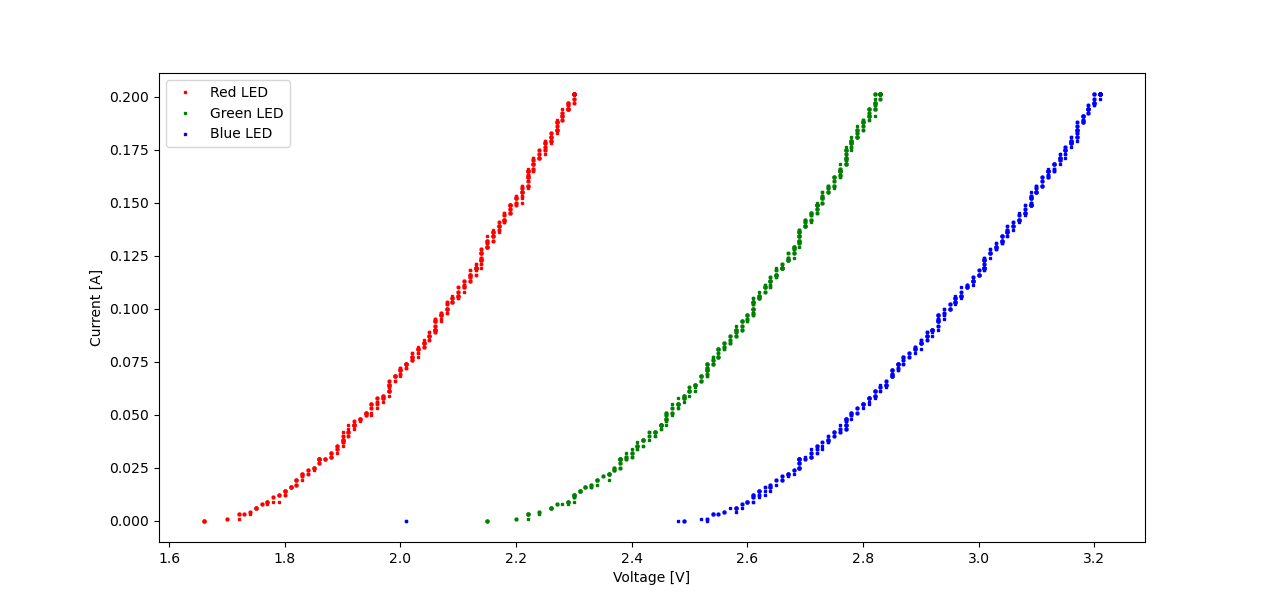
It's based on three calls of the following command.
bin/korad-logger --voltage-limit 5 --current-range '0 0.2 0.001' --save led-$color.log 210
At a sample rate of about 10 Hz and 1 mA / 10 mV resolution, the bench supply won't perform miracles. Nevertheless, it is quite handy. If you measure only current (e.g. in CV mode), or only voltage (CC mode), you can even get near 20 Hz.
Avoiding accidental bricks of MSP430FR launchpads
The MSP430FR launchpad series is a pretty nifty tool both for research and teaching. You get an ultra-low-power 16-bit microcontroller, persistent FRAM, and energy measurement capabilities, all for under $20.
Unfortunately, especially when it comes to teaching, there's one major drawback: Out of bound memory accesses which are off by several thousand bytes can permanently brick the CPU. This typically happens either due to a buffer overflow in FRAM or a stack pointer underflow (i.e., stack overflow) in SRAM.
This issue recently bit one of my students and it turns out that it could have been avoided. So I'll give a quick overview of symptoms, cause, and protection against it, both as a reference for myself and for others.
Symptoms
A bricked MSP430FR launchpad is no longer flashable or erasable via JTAG or BSL. Attempts to control it via MSP Flasher fail with error 16: "The Debug Interface to the device has been secured".
* -----/|-------------------------------------------------------------------- *
* / |__ *
* /_ / MSP Flasher v1.3.20 *
* | / *
* -----|/-------------------------------------------------------------------- *
*
* Evaluating triggers...
* Invalid argument for -i trigger. Default used (USB).
* Checking for available FET debuggers:
* Found USB FET @ ttyACM0 <- Selected
* Initializing interface @ ttyACM0...done
* Checking firmware compatibility:
* FET firmware is up to date.
* Reading FW version...done
* Setting VCC to 3000 mV...done
* Accessing device...
# Exit: 16
# ERROR: The Debug Interface to the device has been secured
* Starting target code execution...done
* Disconnecting from device...done
*
* ----------------------------------------------------------------------------
* Driver : closed (Internal error)
* ----------------------------------------------------------------------------
*/
Unless you know the exact memory pattern written by the buffer overflow (and it specifies a reasonable password length), there is no remedy I'm aware of. The CPU is permanently bricked.
Cause
MSP430FR CPUs use a unified memory architecture: Registers, volatile SRAM, and persistent FRAM are all part of the same address space. This includes fuses (“JTAG signatures”) used to secure the device by either disabling JTAG access altogether or protecting it with a user-defined password.
While write access to several CPU registers requires specific passwords and timing sequences to be observed, this is not the case for the JTAG signatures. Change them, reset the CPU, and it's game over.
The JTAG signatures reside next to the reset vector and interrupt vector at the
16-bit address boundary, within the address range from 0xff80 to 0xffff. On
MSP430FR5994 CPUs, the (writable!) text segment ends at 0xff7f and SRAM is
located in 0x1c00 to 0x3bff. So, a small buffer overflow in a persistent
variable (located in FRAM) or a significant stack pointer underflow (starting in
SRAM, growing down, and wrapping from 0x0000 to 0xffff) may overwrite the
JTAG signatures with arbitrary data.
Protection
MSP430FR CPUs contain a bare-bones Memory Protection Unit. It can partition the
address space into up to three distinct regions with 1kB granularity and
enforce RWX settings for each region. So, if we disallow writes to the 1kB
region from 0xfc00 to 0xffff, we no longer have to worry about accidentally
overwriting the JTAG signatures. To do so, place the following lines in your
startup code:
MPUCTL0 = MPUPW;
MPUSEGB2 = 0x1000; // memory address 0x10000
MPUSEGB1 = 0x0fc0; // memory address 0x0fc00
MPUSAM &= ~MPUSEG2WE; // disallow writes
MPUSAM |= MPUSEG2VS; // reset CPU on violation
MPUCTL0 = MPUPW | MPUENA;
MPUCTL0_H = 0;
Note that this disallows writes not just to the JTAG signatures, but also to
part of the text segment as well as the interrupt vector table. If an
application dynamically alters interrupt vector table entries or uses
persistent FRAM variables at addresses beyond 0xfbff, this method will break
the application. Most practical use cases shouldn't run into this issue.
Monitoring The Things Indoor Gateway (TTIG) via InfluxDB
The Things Indoor Gateway (TTIG) is an affordable LoRaWAN gateway, ideal for getting started with The Things Network or other setups. Here are two ways of monitoring its radio performance and feeding data into e.g. InfluxDB, so you can display the results in a small Grafana dashboard.
TTN Gateway Server API
The Things Stack's Gateway Server API allows requesting uplink and downlink stats of a gateway if you have an appropriate API key.
First, you need to navigate to the gateway page in your TTN console and create a new API key with “View gateway status” rights. Using this key and your gateway ID, you can request connection statistics:
> curl -H "Authorization: Bearer GATEWAY_KEY" \
https://eu1.cloud.thethings.network/api/v3/gs/gateways/GATEWAY_ID/connection/stats | jq
{
"last_uplink_received_at": "2021-09-12T11:00:41.490891018Z",
"uplink_count": "115",
"last_downlink_received_at": "2021-09-12T00:05:45.008438327Z",
"downlink_count": "2",
}
With a cronjob running every few minutes, you can pass the data to InfluxDB. I'm using the following Python script for this:
#!/usr/bin/env python3
# vim:tabstop=4 softtabstop=4 shiftwidth=4 textwidth=160 smarttab expandtab colorcolumn=160
import requests
def main(auth_token, gateway_id):
response = requests.get(
f"https://eu1.cloud.thethings.network/api/v3/gs/gateways/{gateway_id}/connection/stats",
headers={
"Authorization": "Bearer {auth_token}"
},
)
data = response.json()
uplink_count = data.get("uplink_count", 0)
downlink_count = data.get("downlink_count", 0)
requests.post(
"http://influxdb:8086/write?db=hosts",
f"ttn_gateway,name={gateway_id} uplink_count={uplink_count},downlink_count={downlink_count}",
)
if __name__ == "__main__":
main("GATEWAY_KEY", "GATEWAY_ID")
It's also possible to assign “Read gateway traffic” rights to an API key. I didn't play around with that yet.
USB-UART Logs
By soldering a 1kΩ resistor onto R86 on the TTIG PCB, you can enable its built-in CP2102N USB-UART converter. This allows you to use the USB port not just for power, but also for observing its debug output. See Xose Pérez' Hacking the TTI Indoor Gateway blog post for details.
With this hack, connecting the TTIG to a linux computer capable of sourcing up
to 900mA via USB will cause a /dev/ttyUSB serial interface to apper. You can
use tools such as screen or picocom with a baud rate of 115200 to observe
the output. Apart from memory usage and time synchronization logs, it includes
a line similar to the following one for each received LoRa transmission:
RX 868.3MHz DR5 SF7/BW125 snr=9.0 rssi=-46 xtime=0x43000FB11517C3 - updf mhdr=40 DevAddr=01234567 FCtrl=00 FCnt=502 FOpts=[] 0151B4 mic=-1842874694 (15 bytes)
So you can log statistics about Received Signal Strength, Signal-to-Noise Ratio, Spreading Factor and similar.
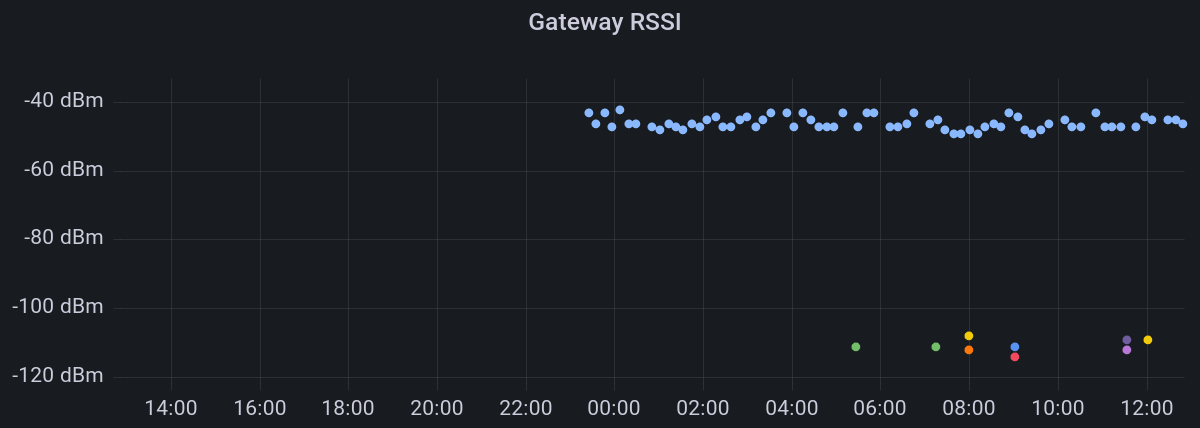
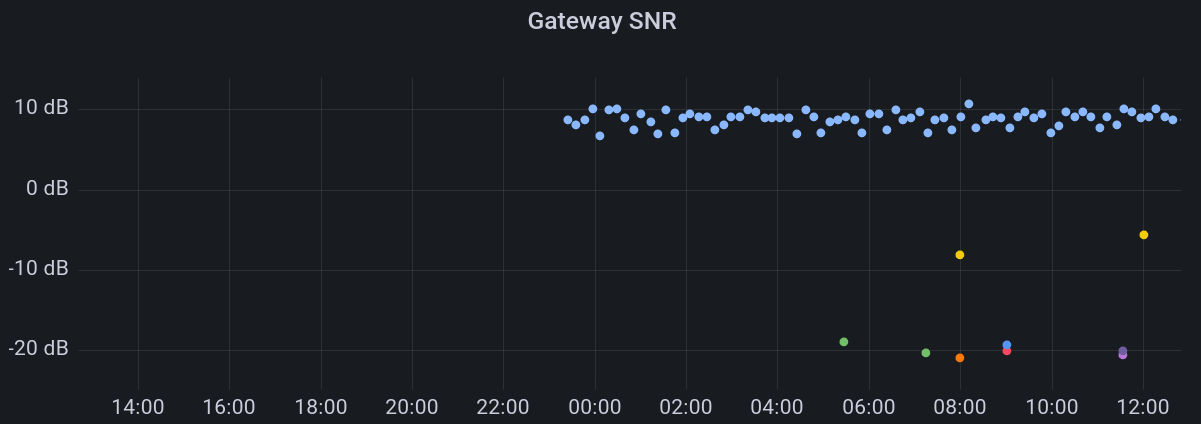
The Python script I'm using for this is somewhat more involved:
#!/usr/bin/env python3
# vim:tabstop=4 softtabstop=4 shiftwidth=4 textwidth=160 smarttab expandtab colorcolumn=160
import re
import requests
import serial
import serial.threaded
import sys
import time
class SerialReader(serial.threaded.Protocol):
def __init__(self, callback):
self.callback = callback
self.recv_buf = ""
def __call__(self):
return self
def data_received(self, data):
try:
str_data = data.decode("UTF-8")
self.recv_buf += str_data
lines = self.recv_buf.split("\n")
if len(lines) > 1:
self.recv_buf = lines[-1]
for line in lines[:-1]:
self.callback(str.strip(line))
except UnicodeDecodeError:
pass
# sys.stderr.write('UART output contains garbage: {data}\n'.format(data = data))
class SerialMonitor:
def __init__(self, port: str, baud: int, callback):
self.ser = serial.serial_for_url(port, do_not_open=True)
self.ser.baudrate = baud
self.ser.parity = "N"
self.ser.rtscts = False
self.ser.xonxoff = False
try:
self.ser.open()
except serial.SerialException as e:
sys.stderr.write(
"Could not open serial port {}: {}\n".format(self.ser.name, e)
)
sys.exit(1)
self.reader = SerialReader(callback=callback)
self.worker = serial.threaded.ReaderThread(self.ser, self.reader)
self.worker.start()
def close(self):
self.worker.stop()
self.ser.close()
if __name__ == "__main__":
def parse_line(line):
match = re.search(
"RX ([0-9.]+)MHz DR([0-9]+) SF([0-9]+)/BW([0-9]+) snr=([0-9.-]+) rssi=([0-9-]+) .* DevAddr=([^ ]*)",
line,
)
if match:
requests.post(
"http://influxdb:8086/write?db=hosts",
data=f"ttn_rx,gateway=GATEWAY_ID,devaddr={match.group(7)} dr={match.group(2)},sf={match.group(3)},bw={match.group(4)},snr={match.group(5)},rssi={match.group(6)}",
)
monitor = SerialMonitor(
"/dev/ttyUSB0",
115200,
parse_line,
)
try:
while True:
time.sleep(60)
except KeyboardInterrupt:
monitor.close()
EFA-APIs mit JSON nutzen
Die meisten deutschen Fahrplanauskünfte nutzen entweder EFA ("Elektronische FahrplanAuskunft") oder HAFAS ("HAcon Fahrplan-Auskunfts-System"). Die meisten EFA-Instanzen wiederum bringen mittlerweile native JSON-Unterstützung mit, so dass sie leicht von Skripten aus nutzbar sind. JSON-APIS wie die von https://vrrf.finalrewind.org sind damit weitgehend obsolet.
Hier ein Python-Beispiel für https://efa.vrr.de:
#!/usr/bin/env python3
import aiohttp
import asyncio
from datetime import datetime
import json
class EFA:
def __init__(self, url, proximity_search=False):
self.dm_url = url + "/XML_DM_REQUEST"
self.dm_post_data = {
"language": "de",
"mode": "direct",
"outputFormat": "JSON",
"type_dm": "stop",
"useProxFootSearch": "0",
"useRealtime": "1",
}
if proximity_search:
self.dm_post_data["useProxFootSearch"] = "1"
async def get_departures(self, place, name, ts):
self.dm_post_data.update(
{
"itdDateDay": ts.day,
"itdDateMonth": ts.month,
"itdDateYear": ts.year,
"itdTimeHour": ts.hour,
"itdTimeMinute": ts.minute,
"name_dm": name,
}
)
if place is None:
self.dm_post_data.pop("place_dm", None)
else:
self.dm_post_data.update({"place_dm": place})
departures = list()
async with aiohttp.ClientSession() as session:
async with session.post(self.dm_url, data=self.dm_post_data) as response:
# EFA may return JSON with a text/html Content-Type, which response.json() does not like.
departures = json.loads(await response.text())
return departures
async def main():
now = datetime.now()
departures = await EFA("https://efa.vrr.de/standard/").get_departures(
"Essen", "Hbf", now
)
print(json.dumps(departures))
if __name__ == "__main__":
asyncio.get_event_loop().run_until_complete(main())
On-demand playback on a remote pulseaudio sink
Setting PULSE_SERVER forwards the entire system audio to a remote (tcp)
network sink. A more fine-granular solution (with control on stream- instead
of system level) is almost as easy, thanks to module-tunnel-sink:
pacmd load-module module-tunnel-sink server=192.168.0.195
Now you can select the remote sink for individual streams (or turn it into the default / fallback one) and, for instance, have two different videos play back on two different remote sinks while your messenger's notification sounds remain local.

Lokalisierung fahrender Züge per GPS
Wer DBF aus einem fahrenden Zug heraus aufruft, kann seit heute nur per GPS-Position Informationen zu diesem Zug erhalten – zumindest in den meisten Fällen und mit ein paar Einschränkungen. Ich möchte hier das Konzept dahinter erläutern.
Da über GTFS derzeit nur Solldaten zur Verfügung stehen und das HAFAS Zugradar lediglich nach beliebigen Fahrten im Umkreis sucht, ohne dabei konkrete Strecken zu berücksichtigen, greift die DBF-Implementierung nicht darauf zurück.
Stattdessen hat sie als einzige API-Abhängigkeit die Ankunfts-/Abfahrtstafel für Bahnhöfe und berechnet alles weitere selbst. Auch bei Abschaltung des HAFAS Zugradars bleibt sie funktionsfähig.
Abbildung von Positionen auf Nachbarstationen
Kern der Lokalisierung ist eine Datenbank, die Deutschland in ca. 200m × 300m große Rechtecke einteilt¹. Für jedes Rechteck, das mindestens eine Bahnstrecke enthält, listet sie alle Bahnhöfe auf, die von einem diese Bahnstrecke passierenden Zug planmäßig als nächstes angefahren werden. Eine Position auf dem Tunnel durch den Teutoburger Wald bei Lengerich enthält beispielsweise unter anderem
- Lengerich (Westf) und Natrup-Hagen (RB66),
- Münster (Westf) Hbf und Osnabrück Hbf (IC/ICE Linien 30 und 31) sowie
- Essen Hbf und Hamburg Hbf (IC-Verbindung Hamburg – Ruhrgebiet ohne Unterwegshalte).
Die Datenbank beruht derzeit überwiegend auf dem von NVBW bereitgestellten SPNV GTFS-Liniennetzplan. Dieser enthält erfreulicherweise auch RE- und RB-Linien außerhalb von Baden-Württembeg. Erweitert wird sie mit einer (leider unfreien und unvollständigen) Menge an IC/ICE- und S-Bahn-Verbindungen. Für Hinweise zu weiteren offenen Datenquellen mit Liniennetzangaben bin ich dankbar.
Bestimmung von Zugkandidaten
Auf Basis einer GPS-Position werden zunächst die Nachbarstationen aus der Datenbank geholt und dann die Ankünfte der nächsten zwei Stunden an jeder Station abgefragt. Dieser Vorgang kann bei einer großen Menge an Stationen einige Sekunden dauern, da die Abfragen nicht parallel stattfinden. Zwar wäre die dadurch ausgelöste zusätzliche Last verglichen mit den restlichen (durch Menschen verursachten) HAFAS-Anfragen noch nicht einmal messbar, zu viele parallele Anfragen von einer einzigen IP dürften aber dennoch nicht gerne gesehen werden.
Für jede Zugfahrt sind Soll- und Ist-Zeit der Ankunft an der angefragten Station sowie die Namen und Soll-Abfahrtszeiten aller vorherigen Stationen bekannt. Züge, die an mehreren der angefragten Stationen verkehren, sind mehrfach vorhanden und werden zu einer einzigen Zugfahrt vereinigt. Nun geht es daran, für jeden Zug abzuschätzen, ob er sich gerade an der angefragten Position befinden könnte oder nicht.
Da die Datenbank mit Paaren von Stationen gefüttert wird, fliegt zunächst jeder Zug raus, der nur eine der angefragten Stationen passiert. Bei solchen Zügen ist sehr wahrscheinlich, dass sie die gesuchte Position auf ihrer Strecke nicht passieren. Anschließend wird für jeden Zug mit Hilfe der (bekannten) Verspätung an der angefragten Station die (unbekannte) verspätung an den vorherigen Unterwegshalten geschätzt und anhand dieser Echtzeitdaten bestimmt, zwischen welchen beiden Unterwegshalten er sich gerade befindet. Ebenso wird für jedes Paar von Unterwegshalten die Entfernung zwischen der angefragten Position und der Luftlinie zwischen den Halten bestimmt.

Jetzt fliegen alle Züge, deren aktuelle geschätzte Position sich nicht zwischen dem Paar von Unterwegshalten mit der kürzesten Entfernung zur angefragten Position befindet. Denn diese sind gerade sehr wahrscheinlich nicht auf dem richtigen Streckenabschnitt. Ebenso werden Züge verworfen, die sich noch an der Startstation befinden und nicht innerhalb der nächsten fünf Minuten losfahren. Eine S-Bahn, die erst in einer Stunde losfährt, ist wohl kaum gerade auf einer Bahnstrecke unterwegs oder auch nur einstiegsbereit am Bahnsteig.
Für die verbleibenden Züge wird die aktuelle Position auf der Luftlinie zwischen ihren Halten geschätzt. Dabei gehe ich von konstanter Geschwindigkeit aus, da ich keine Beschleunigungsprofile oder Streckengeschwindigkeiten kenne. Anschließend werden die Züge sortiert nach der Entfernung zur gesuchten Position aufgelistet.
Genauere Positionsabschätzung
Mit Verwendung des tatsächlichen Linienverlaufs einer Fahrt anstelle der Luftlinie zwischen Unterwegshalten ließe sich die Position noch viel genauer abschätzen und insbesondere bestimmen, ob die Route eines Zuges überhaupt die gesuchte Position enthält – wenn nicht, kann er direkt verworfen werden, auch wenn er nur wenige km neben der gesuchten Position auf einer anderen Bahnstrecke entlangfährt.

Diese Verbesserung ist derzeit nicht implementiert, da das die Menge notwendiger API-Anfragen nochmals erhöhen würde und ich zunächst testen möchte, ob die Ergebnisse mit linearer (Luftlinien-)Interpolation bereits hinreichend nützlich sind. Außerdem kommt es regelmäßig vor, dass das HAFAS die Linie selbst falsch einschätzt und z.B. einen ICE auf einer nicht elektrisierten Nebenbahn (statt der einige km entfernt verlaufenden, aber insgesamt längeren, elektrisierten Hauptbahn) platziert.
Ebenso wäre es auf Dauer interessant, anstelle der Entfernung zur Position die Zeit bis zum Erreichen (oder seit dem Erreichen) der Position als Gütemaß zu verwenden. S-Bahnen und ICE sind ja durchaus unterschiedlich schnell unterwegs. Das steht noch auf der Todo-Liste.
Quelltext
Die Implementierung ist noch ein wenig frickelig und undokumentiert, aber selbstverständlich auf GitHub verfügbar: derf/geolocation-to-train.
Fußnoten
¹ Der Einfachheit halber werden auf drei Nachkommastellen gerundete GPS-Koordinaten genutzt. Das resultierende Gitternetz ist unseren Breitengeraden nicht quadratisch.